免责声明:本文所提及的技术方法和实施过程,仅供爬虫技术学习之用,并不对任何人根据本文全部或部分内容从事的任何行为以及由此行为或不作为所导致的后果承担责任。
我们的任务是从京东商城上根据关键字搜索商品,并获取商品的名称、价格和累计评价信息。
工具列表:爬取工具包括chrome浏览器和pycharm。
Python库:Selenium
01
网站结构分析可以改写为 网站架构分析
在京东首页上,输入关键词“手机”进行搜索:
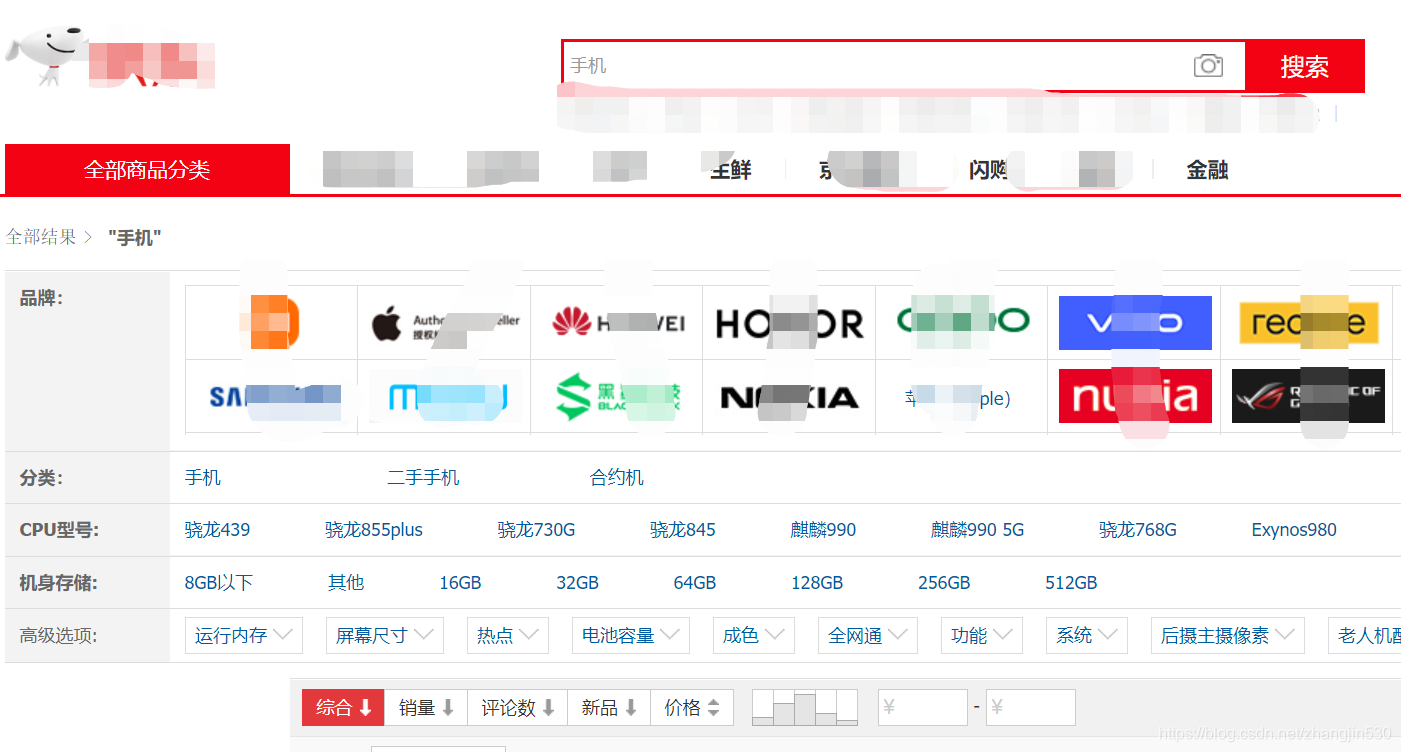
点击相关商品详情页,您可以在详情页上找到所有相关信息。
02
构建Selenium爬虫
打开Pycharm开发工具,新建selenium_jd.py,编写如下代码:
import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.chrome.options import Optionsfrom pyquery import PyQueryoptions = Options();# 去掉自动化控制提示信息options.add_experimental_option("excludeSwitches", ['enable-automation']);user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'options.add_argument('--user-agent=%s' % user_agent)# 去掉自动化控制标识browser = webdriver.Chrome('C:\chromedriver.exe', options=options)browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) """})jd_url = 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=eb248c3d491144a99d93c073ef663455'# 主要页面def start_page(page): # 所有详情页url detail_url_list = [] # 当前页为第一页 current_page = 0 while current_page < page: if (current_page == 0): browser.get(jd_url) else: pass # 设置最大等待时间 wait = WebDriverWait(browser, 30) browser.maximize_window() current_page = current_page + 1start_page(1)
运行代码,能够成功打开京东商品搜索页。
03
提取商品详情页信息
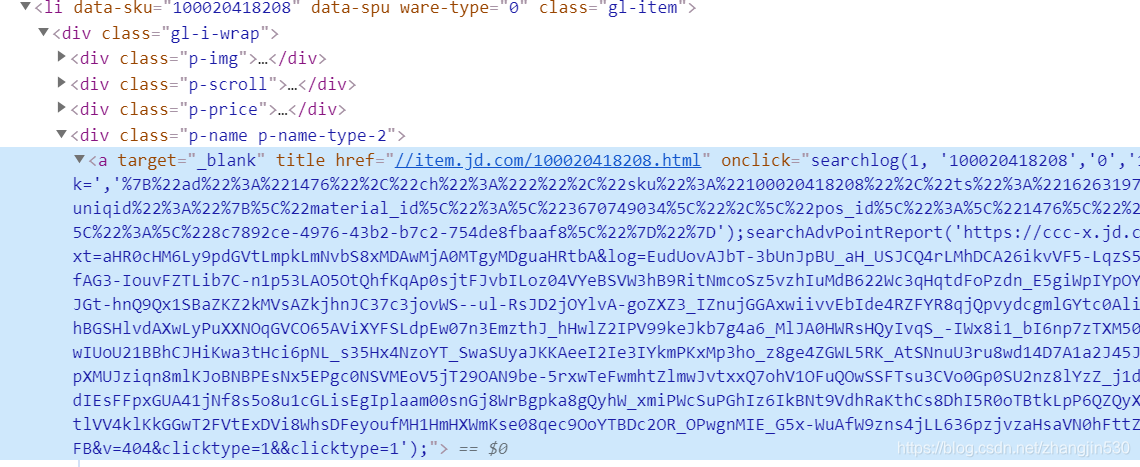
通过对页面进行分析,我们可以找到商品详情页的URL信息。
我是一名全能的文案编辑专家,我将为您改写下面的这段话:
通过编写代码,我们可以轻松地爬取商品详情页的URL。
def get_detail_url(html_source):
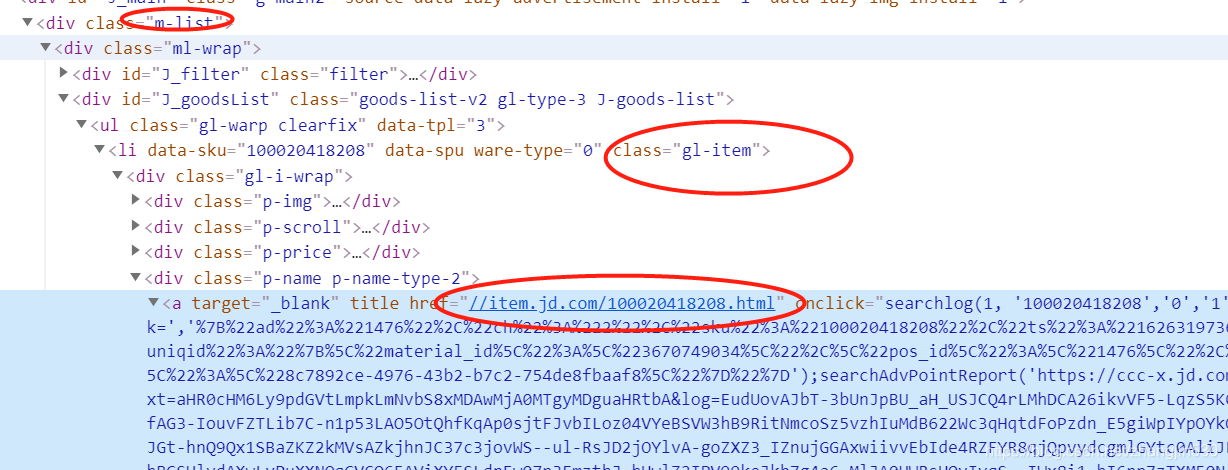
dom = PyQuery(html_source)
items = dom('.m-list .ml-wrap .gl-item').items()
detail_urls = []
for item in items:
detail_urls.append(item.find('.p-name.p-name-type-2 a').attr('href'))
return detail_urls
# 调用商品详情解析方法,运行成功!
04
翻页处理 -> 页面翻转管理
通过慢速下拉页面,才能延迟加载底部的信息。因此,我们需要控制滚动条缓慢下拉,并爬取商品详情页后再进行分页处理。
# 缓慢拉动滚动条拖到底部
window_height = browser.execute_script('return document.body.scrollHeight')
current_height = 0
for i in range(current_height, window_height, 100):
browser.execute_script('window.scrollTo(0, {})'.format(i))
time.sleep(0.5)
# 存储当前爬取的页面详情
urldetail_url_list.extend(get_detail_url(browser.page_source))
# 继续分析分页信息,通过点击下一页实现跳转 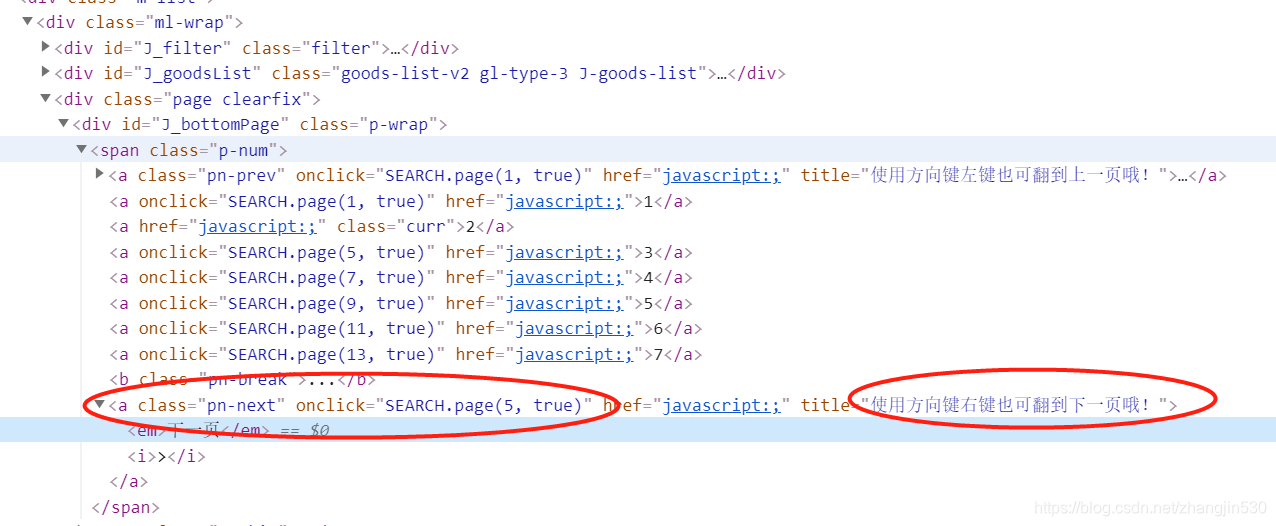
为了方便处理,您可以直接使用鼠标点击来实现跳转。
element = browser.find_element_by_class_name('pn-next')
browser.execute_script("arguments[0].click();", element)
成功运行代码,顺利翻页!
05”
处理商品详情页
当爬取完所有的详情页面URL后,可以打开这些URL来获取详细信息:
```python
# 爬取详情页面信息
def get_detail_info(html_source):
dom = PyQuery(html_source)
detail_dom = dom('.w .itemInfo-wrap')
detail_info = {
'name': detail_dom.find('.sku-name').text(),
'price': detail_dom.find('.summary.summary-first').find('.summary-price-wrap').find('.dd').find('.p-p')
}
```
改写为:
```python
# 获取详情页面信息
def get_detail_info(html_source):
dom = PyQuery(html_source)
detail_dom = dom('.w .itemInfo-wrap')
# 提取详细信息
name = detail_dom.find('.sku-name').text()
price_wrap = detail_dom.find('.summary.summary-first').find('.summary-price-wrap')
# 提取价格信息
price_dd= price_wrap.find('dd')
price_p=price_dd.find('p-p')
# 构建详细信息字典
detail_info ={
'name': name,
'price': price_p.text()
}
return detial_info
``` ```python
# 打开详情页面
def start_detail_page(detail_url_list):
detail_info_list = []
for detail_url in detail_url_list:
browser.get(detail_url)
time.sleep(1)
detail_info_list.append(get_detail_info(browser.page_source))
print(detail_info_list)
```
运行代码后的结果如下: 
成功获取了京东商品信息!
通过微信公众号回复关键字【pachong23】,即可下载所有示例代码!
